¶ Tất tần tật về Cây Phân Đoạn (Segment Tree)
LƯU Ý:
- Khi Segment Tree mới được du nhập vào Việt Nam, một số tài liệu gọi là Interval Tree. Đây là cách gọi không chính xác, bởi Interval Tree là một CTDL khác.
- Tất cả hàm trong bài đều đánh số từ 1. Các nút của cây phân đoạn sẽ quản lý đoạn
- Segment Tree còn có một cách cài đặt khác sử dụng ít bộ nhớ hơn (tối đa phần tử), cài đặt ngắn hơn và chạy nhanh hơn. Tuy nhiên theo cá nhân mình không dễ hiểu bằng cách cài đặt trong bài viết này.
¶ 0. Giới thiệu
Segment Tree là một cấu trúc dữ liệu được sử dụng rất nhiều trong các kỳ thi, đặc biệt là trong những bài toán xử lý trên dãy số.
Segment Tree là một cây. Cụ thể hơn, nó là một cây nhị phân đầy đủ (full binary tree) (mỗi nút là lá hoặc có đúng 2 nút con), với mỗi nút quản lý một đoạn trên dãy số. Với một dãy số gồm phần tử, nút gốc sẽ lưu thông tin về đoạn , nút con trái của nó sẽ lưu thông tin về đoạn và nút con phải sẽ lưu thông tin về đoạn . Tổng quát hơn: nếu nút lưu thông tin đoạn , thì 2 con của nó: và sẽ lưu thông tin của các đoạn và đoạn .
¶ Ví dụ
Xét một dãy gồm 7 phần tử, Segment Tree sẽ quản lý các đoạn như sau:
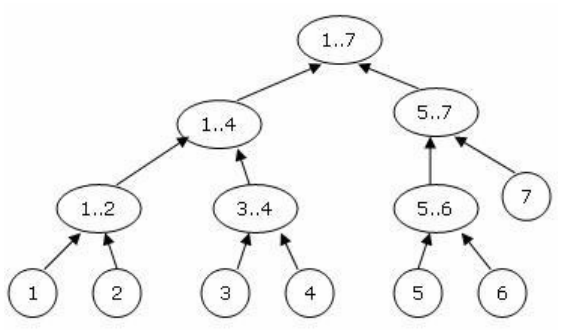
¶ Cài đặt
Để cài đặt, ta có thể dùng một mảng 1 chiều, phần tử thứ nhất của mảng thể hiện nút gốc. Phần tử thứ sẽ có 2 con là (con trái) và (con phải). Với cách cài đặt này, người ta đã chứng minh được bộ nhớ cần dùng cho ST không quá phần tử.
¶ Áp dụng
Để dễ hình dung, ta lấy 1 ví dụ cụ thể:
- Cho dãy phần tử . Ban đầu mỗi phần tử có giả trị 0.
- Có truy vấn . Mỗi truy vấn có 1 trong 2 loại:
- Gán giá trị cho phần tử ở vị trí .
- Tìm giá trị lớn nhất cho đoạn .
Cách đơn giản nhất là dùng 1 mảng duy trì giá trị các phần tử. Với thao tác 1 thì ta gán . Với thao tác 2 thì ta dùng 1 vòng lặp từ đến để tìm giá trị lớn nhất. Rõ ràng cách này có độ phức tạp là và không thể chạy trong thời gian cho phép.
Cách dùng Segment Tree như sau:
- Với truy vấn loại 1, ta sẽ cập nhật thông tin của các nút trên cây ST mà đoạn nó quản lý chứa phần tử .
- Với truy vấn loại 2, ta sẽ tìm tất cả các nút trên cây ST mà đoạn nó quản lý nằm trong , rồi lấy max của các nút này.
Cài đặt như sau:
// Truy vấn: A(i) = v
// Hàm cập nhật trên cây ST, cập nhật cây con gốc id quản lý đọan [l, r]
void update(int id, int l, int r, int i, int v) {
if (i < l || r < i) {
// i nằm ngoài đoạn [l, r], ta bỏ qua nút i
return ;
}
if (l == r) {
// Đoạn chỉ gồm 1 phần tử, không có nút con
ST[id] = v;
return ;
}
// Gọi đệ quy để xử lý các nút con của nút id
int mid = (l + r) / 2;
update(id*2, l, mid, i, v);
update(id*2 + 1, mid+1, r, i, v);
// Cập nhật lại giá trị max của đoạn [l, r] theo 2 nút con:
ST[id] = max(ST[id*2], ST[id*2 + 1]);
}
// Truy vấn: tìm max đoạn [u, v]
// Hàm tìm max các phần tử trên cây ST nằm trong cây con gốc id - quản lý đoạn [l, r]
int get(int id, int l, int r, int u, int v) {
if (v < l || r < u) {
// Đoạn [u, v] không giao với đoạn [l, r], ta bỏ qua đoạn này
return -INFINITY;
}
if (u <= l && r <= v) {
// Đoạn [l, r] nằm hoàn toàn trong đoạn [u, v] mà ta đang truy vấn, ta trả lại
// thông tin lưu ở nút id
return ST[id];
}
int mid = (l + r) / 2;
// Gọi đệ quy với các con của nút id
return max(get(id*2, l, mid, u, v), get(id*2 + 1, mid+1, r, u, v));
}
¶ Phân tích thời gian chạy
Mỗi thao tác truy vấn trên cây ST có độ phức tạp . Để chứng minh điều này, ta xét 2 loại thao tác trên cây ST:
- Truy vấn 1 phần tử trên ST (giống thao tác
updateở trên) - Truy vấn nhiều phần tử trên ST (giống thao tác
getở trên)
Đầu tiên ta có thể chứng minh được:
- Độ cao của cây ST không quá .
- Tại mỗi độ sâu của cây, không có phần tử nào nằm trong 2 nút khác nhau của cây.
¶ Thao tác loại 1
Với thao tác này, ở mỗi độ sâu của cây, ta chỉ gọi đệ quy các con của không quá 1 nút. Phân tích đoạn code trên, ta xét các trường hợp:
- Phần tử cần xét không nằm trong đoạn do nút quản lý. Trường hợp này ta dừng lại, không xét tiếp.
- Phần tử cần xét nằm trong đoạn do nút quản lý. Ta xét các con của nút
id. Tuy nhiên chỉ có 1 con của nútidchứa phần tử cần xét và ta sẽ phải xét tiếp các con của nút này. Với con còn lại, ta sẽ dừng ngay mà không xét các con của nó nữa.
Do đó độ phức tạp của thao tác này không quá .
¶ Thao tác loại 2
Với thao này, ta cũng chứng minh tương tự, nhưng ở mỗi độ sâu của cây, ta chỉ gọi hàm đệ quy với các con của không quá 2 nút.
Ta chứng minh bằng phản chứng, giả sử ta gọi đệ quy với 3 nút khác nhau của cây ST (đánh dấu màu đỏ):
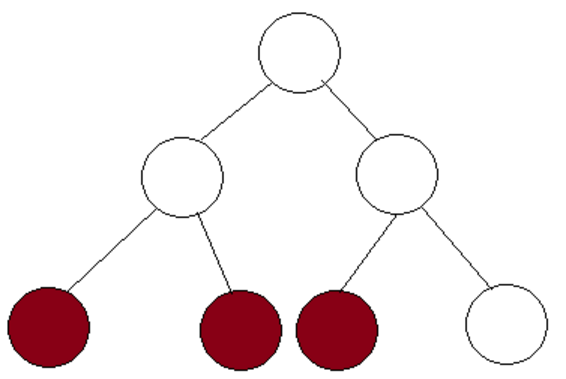
Trong trường hợp này, rõ ràng toàn bộ đoạn của nút ở giữa quản lý nằm trong đoạn đang truy vấn. Do đó ta không cần phải gọi đệ quy các con của nút ở giữa. Từ đó suy ra vô lý, nghĩa là ở mỗi độ sâu ta chỉ gọi đệ quy với không quá 2 nút.
¶ Phân tích bộ nhớ
Ta xét 2 trường hợp:
- : Cây ST đầy đủ, ở độ sâu cuối cùng có đúng lá, và các độ sâu thấp hơn không có nút lá nào (và các nút này đều có đúng 2 con). Như vậy:
- Tầng : có nút
- Tầng : có nút
- ...
Tổng số nút không quá .
- Với và . Số nút của cây ST không quá số nút của cây ST với .
Do đó, số nút của cây cho dãy phần tử, với là không quá , giá trị này xấp xỉ . Bằng thực nghiệm, ta thấy dùng là đủ.
¶ 1. Segment Tree cổ điển
Tại sao lại gọi là cổ điển? Đây là dạng ST đơn giản nhất, chúng ta chỉ giải quyết truy vấn update một phần tử và truy vấn đoạn, mỗi nút lưu một loại dữ liệu cơ bản như số nguyên, boolean, ...
¶ Ví dụ 1
Bài toán: 380C-Codeforces
¶ Tóm tắt đề
Cho một dãy ngoặc độ dài , cho truy vấn có dạng . Yêu cầu của bài toán là với mỗi truy vấn tìm một chuỗi con (không cần liên tiếp) của chuỗi từ đến dài nhất mà tạo thành dãy ngoặc đúng.
¶ Lời giải
Với mỗi nút(ví dụ như nút , quản lý đoạn ) chúng ta lưu ba biến nguyên:
optimal: Là kết quả tối ưu trong đoạn .open: Số lượng dấu(sau khi đã xóa hết các phần tử thuộc dãy ngoặc đúng độ dàioptimaltrong đoạn.close: Số lượng dấu)sau khi đã xóa hết các phần tử thuộc dãy ngoặc đúng độ dàioptimaltrong đoạn.
Ta tạo 1 kiểu dữ liệu cho 1 nút của cây ST như sau:
struct Node {
int optimal;
int open;
int close;
Node(int opt, int o, int c) { // Khởi tạo struct Node
optimal = opt;
open = o;
close = c;
}
};
Và ta khai báo cây ST như sau:
Node st[MAXN * 4];
¶ Định lý
Để tính thông tin ở nút quản lý đoạn , dựa trên 2 nút con và , ta định nghĩa 1 thao tác kết hợp 2 nút của cây ST:
Node operator + (const Node& left, const Node& right) {
Node res;
// min(số dấu "(" thừa ra ở cây con trái, và số dấu ")" thừa ra ở cây con phải)
int tmp = min(left.open, right.close);
// Để xây dựng kết quả tối ưu ở nút id, ta nối dãy ngoặc tối ưu ở 2 con, rồi thêm
// min(số "(" thừa ra ở con trái, số ")" thừa ra ở con phải).
res.optimal = left.optimal + right.optimal + tmp * 2;
res.open = left.open + right.open - tmp;
res.close = left.close + right.close - tmp;
return res;
}
Ban đầu ta có thể khởi tạo cây như sau:
void build(int id, int l, int r) {
if (l == r) {
// Đoạn [l, r] chỉ có 1 phần tử.
if (s[l] == '(') st[id] = Node(0, 1, 0);
else st[id] = Node(0, 0, 1);
return ;
}
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid+1, r);
st[id] = st[id * 2] + st[id * 2 + 1];
}
Để trả lời truy vấn, ta cũng làm tương tự như trong bài toán cơ bản:
Node query(int id, int l, int r, int u, int v) {
if (v < l || r < u) {
// Trường hợp không giao nhau
return Node(0, 0, 0);
}
if (u <= l && r <= v) {
// Trường hợp [l, r] nằm hoàn toàn trong [u, v]
return st[id];
}
int mid = (l + r) / 2;
return query(id * 2, l, mid, u, v) + query(id * 2 + 1, mid+1, r, u, v);
}
¶ Ví dụ 2
Bài toán: SPOJ-KQUERY
Tóm đề:
- Cho một dãy số có phần tử
- Cho truy vấn có dạng 3 số nguyên là . Yêu cầu của bài toán là đếm số lượng số mà .
Giả sử chúng ta có một mảng với nếu và bằng nếu ngược lại. Thì chúng ta có thể dễ dàng trả lời truy vấn bằng cách lấy tổng từ đến .
Cách làm của bài này là xử lý các truy vấn theo một thứ tự khác, để ta có thể dễ dàng tính được mảng . Kĩ năng này được gọi là xử lý offline (tương tự nếu ta trả lời các truy vấn theo đúng thứ tự trong input, thì được gọi là xử lý online):
- Sắp xếp các truy vấn theo thứ tự tăng dần của .
- Lúc đầu mảng gồm toàn bộ các số 1.
- Với mỗi truy vấn, ta xem trong mảng có những phần tử nào lớn hơn giá trị của truy vấn trước, và nhỏ hơn giá trị của truy vấn hiện tại, rồi đánh dấu các vị trí đó trên mảng thành 0. Để làm được việc này một cách hiệu quả, ta cũng cần sắp xếp lại mảng theo thứ tự tăng dần.
Ta tạo kiểu dữ liệu cho truy vấn:
struct Query {
int k;
int l, r;
};
// so sánh 2 truy vấn để dùng vào việc sort.
bool operator < (const Query& a, const Query &b) {
return a.k < b.k;
}
Phần xử lý chính sẽ như sau:
vector< Query > queries; // các truy vấn
// Đọc vào các truy vấn
readInput();
// Sắp xếp các truy vấn
sort(queries.begin(), queries.end());
// Khởi tạo mảng id sao cho:
// a[id[1]], a[id[2]], a[id[3]] là mảng a đã sắp xếp tăng dần.
// Khởi tạo Segment Tree
for(Query q : queries) {
while (a[id[i]] <= q.k) {
b[id[i]] = 0;
// Cập nhật cây Segment Tree.
++i;
}
}
Vậy ta có thể viết hàm xây dựng cây như sau:
void build(int id, int l, int r) {
if (l == r) {
// Nút id chỉ gồm 1 phần tử
st[id] = 1;
return ;
}
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid+1, r);
st[id] = st[id*2] + st[id*2+1];
}
Một hàm cập nhật khi ta muốn gán lại một vị trí bằng 0:
void update(int id, int l, int r, int u) {
if (u < l || r < u) {
// u nằm ngoài đoạn [l, r]
return ;
}
if (l == r) {
st[id] = 0;
return ;
}
int mid = (l + r) / 2;
update(id*2, l, mid, u);
update(id*2 + 1, mid+1, r, u);
st[id] = st[id*2] + st[id*2+1];
}
Và cuối cùng là thực hiện truy vấn lấy tổng một đoạn:
int get(int id, int l, int r, int u, int v) {
if (v < l || r < u) {
// Đoạn [l, r] nằm ngoài đoạn [u, v]
return 0;
}
if (u <= l && r <= v) {
// Đoạn [l, r] nằm hoàn toàn trong đoạn [u, v]
return st[id];
}
int mid = (l + r) / 2;
return get(id*2, l, mid, u, v)
+ get(id*2+1, mid+1, r, u, v);
}
¶ 2. Lazy Propagation
Đây là kĩ thuật được sử dụng trong ST để giảm độ phức tạp của ST với các truy vấn cập nhật đoạn.
¶ Tư tưởng
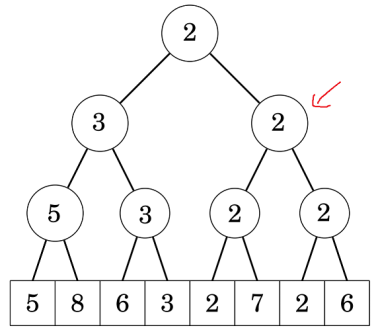
Giả sử ta cần cập nhật đoạn . Dễ thấy ta không thể nào cập nhật tất cả các nút trên Segment Tree (do tổng số nút nằm trong đoạn có thể lên đến ). Do đó, trong quá trình cập nhật, ta chỉ thay đổi giá trị ở các nút quản lý các đoạn to nhất nằm trong . Ví dụ với , cây Segment tree như hình minh hoạ ở đầu bài. Giả sử bạn cần cập nhật :
- Bạn chỉ cập nhật giá trị ở các nút quản lý các đoạn và .
- Giá trị của các nút quản lý các đoạn , , , , , ... sẽ không đúng. Ta sẽ chỉ cập nhật lại giá trị của các nút này khi thật sự cần thiết (Do đó kĩ thuật này được gọi là lazy - lười biếng).
Cụ thể, chúng ta cùng xem bài toán sau:
¶ Bài Toán
¶ Tóm tắt đề
Cho dãy số với phần tử . Bạn cần thực hiện 2 loại truy vấn:
- Cộng tất cả các số trong đoạn lên giá trị .
- In ra giá trị lớn nhất của các số trong đoạn .
¶ Phân tích
Thao tác 2 là thao tác cơ bản trên Segment Tree, đã được ta phân tích ở bài toán đầu tiên.
Với thao tác 1, truy vấn đoạn . Giả sử ta gọi là giá trị lớn nhất trong đoạn mà nút quản lý. Trong lúc cập nhật, muốn hàm này thực hiện với độ phức tạp không quá , thì khi đến 1 nút quản lý đoạn với đoạn nằm hoàn toàn trong đoạn , thì ta không được đi vào các nút con của nó nữa (nếu không độ phức tạp sẽ là do ta đi vào tất cả các nút nằm trong đoạn ). Để giải quyết, ta dùng kĩ thuật Lazy Propagation như sau:
- Lưu với ý nghĩa, tất cả các phần tử trong đoạn mà nút quản lý đều được cộng thêm .
- Trước khi ta cập nhật hoặc lấy 1 giá trị của 1 nút nào đó, ta phải đảm bảo ta đã "đẩy" giá trị của mảng ở tất cả các nút tổ tiên của xuống . Để làm được điều này, ở các hàm
getvàupdate, trước khi gọi đệ quy xuống các con và , ta phải gán:T[id*2] += T[id]T[id*2+1] += T[id]T[id] = 0chú ý ta cần phải thực hiện thao tác này, nếu không mỗi phần tử của dãy sẽ bị cộng nhiều lần, do ta đẩy xuống nhiều lần.
Chú ý: Bài QMAX2 này có cách cài đặt khác không sử dụng Lazy Propagation, tuy nhiên sẽ không được trình bày ở đây.
¶ Cài đặt
Ta có kiểu dữ liệu cho 1 nút của ST như sau:
struct Node {
int lazy; // giá trị T trong phân tích trên
int val; // giá trị lớn nhất.
} nodes[MAXN * 4];
Hàm "đẩy" giá trị xuống các con:
void down(int id) {
int t = nodes[id].lazy;
nodes[id*2].lazy += t;
nodes[id*2].val += t;
nodes[id*2+1].lazy += t;
nodes[id*2+1].val += t;
nodes[id].lazy = 0;
}
Hàm cập nhật:
void update(int id, int l, int r, int u, int v, int val) {
if (v < l || r < u) {
return ;
}
if (u <= l && r <= v) {
// Khi cài đặt, ta LUÔN ĐẢM BẢO giá trị của nút được cập nhật ĐỒNG THỜI với
// giá trị lazy propagation. Như vậy sẽ tránh sai sót.
nodes[id].val += val;
nodes[id].lazy += val;
return ;
}
int mid = (l + r) / 2;
down(id); // đẩy giá trị lazy propagation xuống các con
update(id*2, l, mid, u, v, val);
update(id*2+1, mid+1, r, u, v, val);
nodes[id].val = max(nodes[id*2].val, nodes[id*2+1].val);
}
Hàm lấy giá trị lớn nhất:
int get(int id, int l, int r, int u, int v) {
if (v < l || r < u) {
return -INFINITY;
}
if (u <= l && r <= v) {
return nodes[id].val;
}
int mid = (l + r) / 2;
down(id); // đẩy giá trị lazy propagation xuống các con
return max(get(id*2, l, mid, u, v),
get(id*2+1, mid+1, r, u, v));
// Trong các bài toán tổng quát, giá trị ở nút id có thể bị thay đổi (do ta đẩy lazy propagation
// xuống các con). Khi đó, ta cần cập nhật lại thông tin của nút id dựa trên thông tin của các con.
}
Đến đây các bạn đã nắm được kiến thức cơ bản về Segment Tree. Những phần tiếp theo nói về các kiến thức nâng cao - các mở rộng của ST. Bạn nên làm nhiều bài luyện tập (tham khảo ở cuối bài) trước khi nghiên cứu tiếp.
¶ 3. Ứng dụng với cấu trúc mảng động
Trong loại bài toán này với mỗi nút của cây ta lưu lại một vector và một số biến khác.
¶ Ví dụ
Cách làm online cho bài KQUERY.
¶ Tóm tắt đề
- Cho dãy với phần tử. Cần trả lời truy vấn.
- Truy vấn: đếm số phần tử lớn hơn trong đoạn .
- Giới hạn:
¶ Phân tích
- Có nút mà ta cần xét khi trả lời truy vấn của đoạn .
- Nếu trên mỗi nút chúng ta có thể lưu lại danh sách các phần tử đó theo thứ tự tăng dần, ta có thể tìm ra kết quả ở mỗi nút bằng tìm kiếm nhị phân.
Vì thế với mỗi nút ta lưu lại một vector chứa các phần tử từ đến theo thứ tự tăng dần. Điều này có thể được thực hiện với bộ phức tạp bộ nhớ là do mỗi phần tử có thể ở tối đa nút (độ sâu của cây không quá ). Ở mỗi nút cha có ta có thể gộp hai nút con vào nút cha bằng phương pháp giống như Merge Sort (lưu lại hai biến chạy và so sánh lần lượt từng phần tử ở hai mảng) để có thể xây dựng cây trong .
Hàm xây cây có thể được như sau:
void build(int id, int l, int r) {
if (l == r) {
// Đoạn gồm 1 phần tử. Ta dễ dàng khởi tạo nút trên ST.
st[id].push_back(a[l]);
return ;
}
int mid = (l + r) / 2;
build(id*2, l, mid);
build(id*2+1, mid+1, r);
merge(st[id*2].begin(), st[id*2].end(), st[id*2+1].begin(), st[id*2+1].end(), st[id].begin());
}
Và hàm truy vấn có thể cài đặt như sau:
int get(int id, int l, int r, int u, int v, int k) { // Trả lời truy vấn (x, y, k)
if (v < l || r < u) {
return 0;
}
if (u <= l && r <= v) {
// Đếm số phần tử > K bằng chặt nhị phân
return st[id].size() - (upper_bound(st[id].begin(), st[id].end(), k) - st[id].begin());
}
int mid = (l + r) / 2;
return get(id*2, l, mid, u, v, k) + get(id*2+1, mid+1, r, u, v, k);
}
Một ví dụ khác là bài Component Tree
¶ 4. Ứng dụng với cấu trúc set
Ở cấu trúc này mỗi nút chúng ta lưu một set,multiset, hashmap, hoặc unodered map và một số biến khác.
Đây là một bài toán ví dụ:
Cho vector rỗng ban đầu. Chúng ta có thể thực hiện truy vấn trên những vector này:
- Truy vấn là thêm số vào cuối vector .
- Truy vấn là xuất ra , với là số lần xuất hiện của số trong vector .
Bài toán này chúng ta lưu lại mỗi nút của cây là một multiset , với mỗi nút lưu số đúng lần với độ phức tạp bộ nhớ chỉ .
Với mỗi truy vấn chúng ta sẽ in ra tổng của tất cả dùng cây phân đoạn và truy vấn trên set trong mỗi đoạn thuộc đoạn đến như truy trên truy vấn cây phân đoạn bình thường.
Chúng ta sẽ không có hàm xây cây do các vector ban đầu đang là rỗng, nhưng chúng ta sẽ có thêm hàm cộng phần tử vào như sau:
void add(int id, int l, int r, int p, int k) { // Thực hiện truy vấn A p k
s[id].insert(k);
if (l == r) return ;
int mid = (l + r) / 2;
if (p <= mid) add(id*2, l, mid, p, k);
else add(id*2 + 1, mid+1, r, p, k);
}
Và một hàm cho truy vấn 2:
int ask(int id, int l, int r, int x, int y, int k) { // Trả lời C x y k
if (y < l || r < x) return 0;
if (x <= l && r <= y) {
return s[id].count(k);
}
int mid = (l + r) / 2;
return ask(id*2, l, mid, x, y, k) + ask(id*2+1, mid+1, r, x, y, k);
}
¶ 5. Ứng dụng với các cấu trúc dữ liệu khác
Cây phân đoạn còn có thể có thể sử dụng một cách linh hoạt với các cấu trúc dữ liệu khác như ở trên. Sử dụng một cây phân đoạn khác trên từng nút có thể giúp chúng ta truy vấn dễ dàng hơn trên mảng hai chiều. Trên đây cũng có thể là các loại cây như Cây tiền tố(Trie) hoặc cũng có thể là cấu trúc Disjoint Set. Sau đây mình xin giới thiệu một loại cây khác cũng sử dụng nhiều trong cây phân đoạn đó chính là Cây Fenwick (Binary Indexed Tree):
Như trên mỗi nút của cây sẽ là một cây Fenwick và có thể một số biến khác. Dưới đây là một bài toán ví dụ:
Cho vectors rỗng ban đầu. Chúng ta cần thực hiện hai loại truy vấn:
- Truy vấn là thêm số vào đằng sau vector .
- Truy vấn là xuất ra với với là số lần xuất hiện trong .
Với bài toán này, ta cũng lưu lại ở một nút là một vector chứa số khi và chỉ khi (độ phức tạp bộ nhớ sẽ là ) (các số theo theo thứ tự tăng dần)
Đầu tiên, đọc và lưu các truy vấn lại với mỗi truy vấn loại 1 ta sẽ thêm vào tất cả vector có chứa phần tử . Sau đó ta tiến hành sắp xếp các truy vấn theo phương pháp Merge Sort đã nói ở trên và dùng hàm unique để loại các phần tử trùng.
Sau đó chúng ta sẽ xây dụng ở mỗi nút một cây Fenwick có độ lớn bằng độ dài vector. Sau đây là hàm thêm giá trị:
void insert(int id, int l, int r, int p, int k) { // Thực hiện A p k
if (l == r) {
v[id].push_back(k);
return ;
}
int mid = (l+r) / 2;
if (p < mid)
insert(id*2, l, mid, p, k);
else
insert(id*2+1, mid+1, r, p, k);
}
Hàm sắp xếp sau khi đã đọc hết các truy vấn:
void sort_(int id, int l, int r) {
if (l == r) return ;
int mid = (l + r) / 2;
sort_(id*2, l, mid);
sort_(id*2+1, mid+1, r);
merge(v[2 * id].begin(), v[2 * id].end(), v[2 * id + 1].begin(), v[2 * id +1].end(), v[id].begin());
}
Với mỗi truy vấn loại 1 ta làm như sau với mỗi nút x:
for(int i = a + 1; i < fen[x].size(); i += i & -i)
fen[x][i] ++;
Với tất cả :
void update(int id, int l, int r, int p, int k) {
int a = lower_bound(v[id].begin(), v[id].end(), k) - v[id].begin();
for(int i = a + 1; i < fen[id].size(); i += i & -i)
fen[id][i]++;
if (l == r) return ;
int mid = (l + r) / 2;
if (p < mid)
update(id*2, l, mid, p, k);
else
update(id*2+1, mid+1, r, p, k);
}
Còn lại việc tính toán truy vấn loại 2 trở nên dễ dàng hơn:
int ask(int id, int l, int r, int x, int y, int k) { // Trả lời C x y-1 k
if (y < l || r < x) return 0;
if (x <= l && r <= y) {
int a = lower_bound(v[id].begin(), v[id].end(), k) - v[id].begin();
int ans = 0;
for(int i = a + 1; i > 0; i -= i & -i)
ans += fen[id][i];
return ans;
}
int mid = (l + r) / 2;
return ask(id*2, l, mid, x, y, k)
+ ask(id*2+1, mid+1, r, x, y, k);
}
¶ 6. Ứng dụng trong cây có gốc
Ta có thể thấy cây phân đoạn là một ứng dụng trong mảng, vì lí do đó nếu chúng ta có thể đổi cây thành các mảng, ta có thể dễ dàng xử lý các truy vấn trên cây. Đây là tư tưởng của Heavy Light Decomposition.
Bài tập ví dụ: 396C - On Changing Tree
Gọi là độ cao tương ứng của nút .
Ta có với mỗi nút trong cây con gốc sau truy vấn một giá trị của nó sẽ tăng một lượng là . Kết quả của truy vấn 2 sẽ là . Vì vậy ta chỉ cần tính hai giá trị là và . Vậy với mỗi nút ta có thể lưu lại hai giá trị là và (không cần lazy propagation do chúng ta chỉ update nút đầu tiên thỏa việc nằm trong đoạn.
Với truy vấn cập nhật:
void update(int id, int l, int r, int x, int k, int v) {
if (s[v] >= r || l >= f[v]) return ;
if (s[v] <= l && r <= f[v]) {
hkx[id] = (hkx[id] + x) % mod;
int a = (1LL * h[v] * k) % mod;
hkx[id] = (hkx[id] + a) % mod;
sk[id] = (sk[id] + k) % mod;
return ;
}
int mid = (l+r) / 2;
update(id*2, l, mid, x, k, v);
update(id*2+1, mid+1, r, x, k, v);
}
Và truy vấn:
int ask(int id, int l, int r, int v) {
int a = (1LL * h[v] * sk[id]) % mod;
int ans = (hkx[id] + mod - a) % mod;
if (l == r) return ans;
int mid = (l+r) / 2;
if(s[v] < mid)
return (ans + ask(2 * id, l, mid, v)) % mod;
return (ans + ask(2*id + 1, mid, r, v)) % mod;
}
¶ 7. Persistent Segment Trees
Persistent Data Structures là những cấu trúc dữ liệu được dùng khi chúng ta cần có toàn bộ lịch sử của các thay đổi trên 1 cấu trúc dữ liệu (CTDL).
Các bạn có thể đọc thêm ở: Persistent Data Structures
¶ 8. IT đoạn thẳng
Bài toán
Cho một tập hợp chứa các đường thẳng có dạng , mỗi đường thẳng được biểu diễn bằng một cặp số . Cần thực hiện hai truy vấn:
- Thêm một đường thẳng vào tập hợp.
- Trả lời xem tại hoành độ , điểm nào thuộc ít nhất một đường thẳng trong tập có tung độ lớn nhất. Nói cách khác, đường thẳng nào có lớn nhất.
Để giải bài toán này, hai cách phổ biến là ứng dụng bao lồi và sử dụng cây Interval Tree lưu đoạn thẳng
¶ 9. Chặt nhị phân trên Segment tree
Nguồn: Binary Search on Segment Tree
Đây là một thao tác khá thường gặp khi dùng Segment tree, nó có tên gọi là chặt nhị phân trên Segment tree, tên tiếng anh là "Binary search over/on Segment tree", hoặc là "Walk on Segment tree".
Trước hết, ta cần phải nắm được kiến thức cơ bản về Segment tree và chặt nhị phân. Bạn có thể tìm hiểu thuật toán chặt nhị phân ở đây.
¶ Bài toán 1
Cho một mảng các số nguyên có phần tử. Có truy vấn có dạng:
- : tìm nhỏ nhất sao cho .
¶ Cách giải
Ta nhận thấy do và nhỏ nhất, cho nên với mọi .
Do đó, .
Đặt .
Nhận xét 1: Việc tìm nhỏ nhất sao cho cũng tương ứng với việc tìm nhỏ nhất sao cho .
Nhận xét 2: . Nói cách khác, là mảng không tăng.
Vậy bài toán có thể phát biểu lại như sau:
Cho một mảng các số nguyên đã "sắp xếp" giảm dần, có truy vấn có dạng:
- : tìm nhỏ nhất sao cho .
Rõ ràng bài toán này chỉ là bài toán chặt nhị phân cơ bản, vì mảng đã được "sắp xếp". Tới đây ta có thể trả lời các truy vấn trong độ phức tạp . Code thì nó sẽ giống giống thế này:
int query(int k) {
int l = 1, r = n, pos = -1;
while (l <= r) {
int mid = (l + r) / 2;
if (f[mid] <= k)
pos = mid, r = mid - 1;
else
l = mid + 1;
}
return pos;
}
¶ Bài toán 2
Cho một mảng các số nguyên có phần tử. Có truy vấn có dạng:
- : gán .
- : tìm nhỏ nhất sao cho
Bài toán này giống bài toán 1, nhưng có thêm truy vấn cập nhật phần tử, điều này làm cho mảng bị thay đổi. Ta có thể sửa lại yêu cầu bài toán một chút, là có loại truy vấn:
- : gán .
- : tìm nhỏ nhất sao cho
- : tính .
Rõ ràng truy vấn 1 và 3 có thể thực hiện bằng Segment tree với độ phức tạp , vậy thì tới đây bài toán quay về bài toán 1, chỉ có điều khi ta cần tính thì ta phải gọi hàm trên Segment tree để lấy min, độ phức tạp cho việc trả lời truy vấn 2 là :
int query(int k) {
int l = 1, r = n, pos = -1;
while (l <= r) {
int mid = (l + r) / 2;
if (getMin(1, mid) <= k)
pos = mid, r = mid - 1;
else
l = mid + 1;
}
return pos;
}
Nhưng nếu chỉ dừng ở đây thì đã không cần phải nhắc đến trong bài viết này rồi <(") . Ta nhìn một chút vào cấu trúc cây Segment tree (quản lý min) dưới dây:
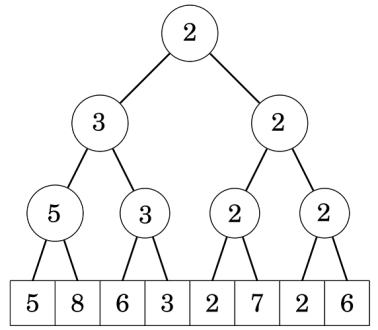
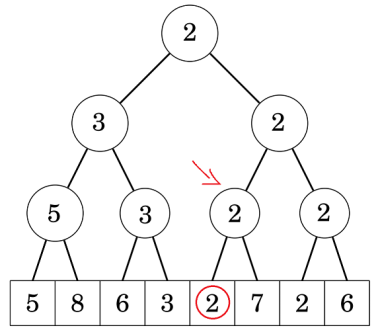
Giả sử ta cần tìm vị trí đầu tiên có giá trị không vượt quá . Ta đứng từ gốc, xét con trái phải lần lượt có giá trị là và :
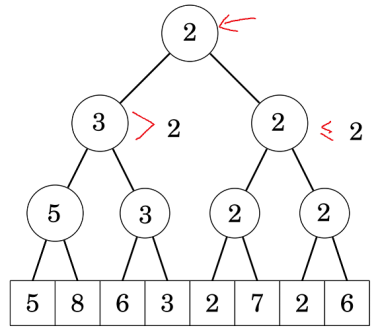
Do ta đang cần tìm giá trị không vượt quá , nên ta chắc chắn kết quả không nằm trong cây con bên trái (vì min của cây con này là , suy ra mọi phần tử được quản lý bởi cây con này đều lớn hơn ). Và do cây con phải có giá trị là , suy ra kết quả chắc chắn nằm cây con này, ta đệ quy xuống cây con bên trái:
Tương tự, cây con này có cây con trái và phải, cả đều có giá trị là , nghĩa là luôn tồn tại ít nhất một số có giá trị bằng trong cả cây con này, từ đó suy ra cả cây con đều có thể chứa kết quả ta cần tìm. Nhưng do ta muốn tìm vị trí có bé nhất, nên ta sẽ ưu tiên đi vào cây con bên trái (cây con này quản lý các vị trí nhỏ hơn các vị trí của cây con phải).
Lập luận tương tự thì ta sẽ biết được kết quả nằm ở cây con trái, lúc này cây chỉ quản lý duy nhất một phần tử nên ta có thể kết luận luôn vị trí cần tìm.
Đoạn code mẫu cho việc tìm vị trí đầu tiên không vượt quá số có thể code như sau, lưu ý, trong code này mình xem mảng là mảng lưu giá trị của Segment tree, tham số thể hiện cho việc nút quản lý một đoạn từ :
int query(int root, int l, int r, int k) {
if (st[root] > k) return -1; //nếu cả đoạn [l, r] đều lớn hơn k thì không thỏa mãn
if (l == r) return l; //khi đoạn có 1 phần tử thì đó là kết quả
int mid = (l + r) / 2;
if (st[root * 2] <= k) //nếu min cây con trái không vượt quá k
return query(root * 2, l, mid, k);
//ngược lại thì kết quả nằm ở bên cây con phải
return query(root * 2 + 1, mid + 1, r, k)
}
//cout << query(1, 1, n, k);
Hàm trên có độ phức tạp là , bởi vì mỗi lần đệ quy chỉ gọi ra một hàm khác (từ một nút chỉ đi qua một nút khác), và số lần gọi đệ quy chính bằng độ cao của Segment tree.
Tới đây ta đã xong bài toán 2.
Lưu ý là, với các bài toán mà truy vấn cập nhật là một đoạn (thay vì một phần tử như bài toán 2), thì việc cài đặt hàm ở trên vẫn không đổi, chỉ có thêm vào lazy trước khi xét cây con trái phải, mình xin giành cho bạn đọc vậy.
¶ Bài toán 3:
Cho một mảng các số nguyên có phần tử. Có truy vấn có dạng:
- : gán .
- : tìm nhỏ nhất sao cho và
Bài toán này khó hơn bài toán 2 một chút, đó là có thêm một cận dưới của (thay vì tìm bé nhất, thì ta cần tìm bé nhất nhưng lớn hơn một số nào đó), ta có thể thay đổi code một tí như sau:
int query(int root, int l, int r, int lowerbound, int k) {
if (st[root] > k) return -1; //nếu cả đoạn [l, r] đều lớn hơn k thì không thỏa mãn
if (r < lowerbound) return -1; //ta chỉ xét những vị trí không nhỏ hơn lowerbound
if (l == r) return l; //khi đoạn có 1 phần tử thì đó là kết quả
int mid = (l + r) / 2;
int res = -1;
if (st[root * 2] <= k) //nếu min cây con trái không vượt quá k
res = query(root * 2, l, mid, lowerbound, k);
//nếu cây con trái không tìm được kết quả <=> min nằm ngoài lowerbound
//thì ta sẽ tìm kết quả ở cây con phải
if (res == -1)
res = query(root * 2 + 1, mid + 1, r, lowerbound, k);
return res;
}
//cout << query(1, 1, n, l, k);
Code này có một chút lạ, khác so với code ở bài toán 2 một chút, ở bài toán 2, thì mỗi lần đệ quy chỉ thăm duy nhất một con trái hoặc phải, nhưng ở code mới này thì một lần đệ quy có thể phải thăm cả con, lý do là vì có thể một cây con nó có min không vượt quá , nhưng vị trí đạt min nó có thể nhỏ hơn , vì thế ta phải tìm ở cây con khác.
Để đánh giá độ phức tạp code trên thì hơi rườm rà một chút, nhưng nó vẫn là . Đại ý là ta có thể chứng minh số lần mà sẽ không quá .
¶ Bài tập áp dụng:
- VNOJ - Educational Segment Tree Contest
- VNOJ - QMAX
- VNOJ - NKLINEUP
- VNOJ - GSS
- VNOJ - LITES
- VNOJ - DQUERY
- VNOJ - KQUERY
- FREQUENT
- VNOJ - KQUERY2
- GSS2
- GSS3
- MULTQ3
- POSTERS
- PATULJCI
- New Year Domino
- Copying Data
- DZY Loves Fibonacci Numbers
- FRBSUM