¶ Bài toán RMQ và bài toán LCA
Nguồn: Topcoder
Trong bài viết này, tác giả sẽ giới thiệu với bạn 2 bài toán cơ bản: Bài toán RMQ và bài toán LCA, cũng như mối liên hệ giữa 2 bài toán này.
¶ Các định nghĩa
Gỉa sử thuật toán có thời gian tiền xử lý là và thời gian trả lời 1 truy vấn là . Ta ký hiệu độ phức tạp tổng quát của thuật toán là .
Trong bài này, khi viết , chúng ta hiểu là log cơ số 2 của .
¶ Bài toán Range Minimum Query (RMQ)
Cho mảng . Bạn cần trả lời truy vấn. Mỗi truy vấn gồm 2 số , và bạn cần đưa ra vị trí của phần tử có giá trị nhỏ nhất trong đoạn từ đến của mảng , ký hiệu là .
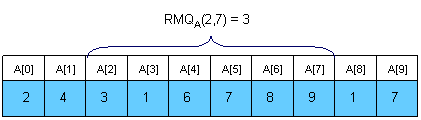
¶ Bài toán Lowest Common Ancestor (LCA)
Cho cây có gốc . Bạn cần trả lời truy vấn. Mỗi truy vấn gồm 2 số , và bạn cần tìm nút xa gốc nhất mà là tổ tiên của cả 2 nút và , ký hiệu là .

¶ Bài toán RMQ
¶ Thuật toán
Thuật toán hiển nhiên nhất cho bài RMQ là ta không cần tiền xử lý gì cả. Với mỗi truy vấn, ta xét lần lượt từng phần tử từ đến để tìm phần tử nhỏ nhất. Hiển nhiên, độ phức tạp thuật toán này là .
¶ Thuật toán
Lưu giá trị của trong một bảng .
Thuật toán sẽ có độ phức tạp . Tuy nhiên ta có thể sử dụng quy hoạch động để giảm độ phức tạp xuống như sau:
for i = 0 .. N-1
M[i][i] = i;
for i = 0 .. N-1
for j = i+1 .. N-1
if (A[M[i][j - 1]] < A[j])
M[i][j] = M[i][j - 1];
else
M[i][j] = j;
Có thể thấy thuật toán này khá chậm và tốn bộ nhớ nên sẽ không hữu ích với những dữ liệu lớn hơn.
¶ Thuật toán
Ta có thể chia mảng thành phần. Ta sử dụng một mảng để lưu giá trị mỗi phần. có thể dễ dàng tính được trong :
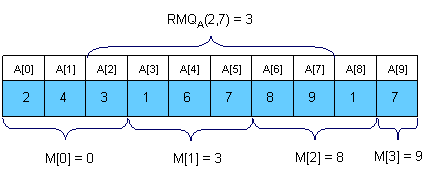
Để tính , chúng ta xét giá trị của phần nằm trong đoạn , và những phần tử ở đầu và cuối đoạn là giao giữa các phần. Ví dụ, để tính ta chỉ cần so sánh , , và .
Dễ thấy thuật toán không sử dụng quá phép toán cho mỗi truy vấn.
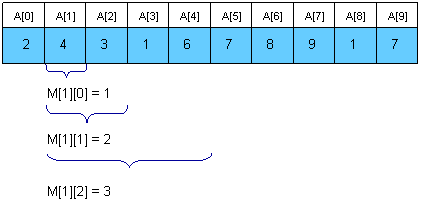
¶ Sparse Table (ST)
Đây là một hướng tiếp cận tốt hơn để tiền xử lý cho các đoạn con có độ dài , sử dụng quy hoạch động.
Ta sử dụng mảng với là chỉ số của phần tử có giá trị nhỏ nhất trong đoạn có độ dài và bắt đầu ở . Ví dụ:
Để tính , ta xét của 2 nửa đầu và nửa cuối của đoạn, mỗi phần sẽ có độ dài :
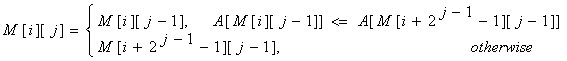
void process2(int M[MAXN][LOGMAXN], int A[MAXN], int N)
{
int i, j;
// Khởi tạo M với các khoảng độ dài 1
for (i = 0; i < N; i++)
M[i][0] = i;
// Tính M với các khoảng dài 2^j
for (j = 1; 1 << j <= N; j++)
for (i = 0; i + (1 << j) - 1 < N; i++)
if (A[M[i][j - 1]] < A[M[i + (1 << (j - 1))][j - 1]])
M[i][j] = M[i][j - 1];
else
M[i][j] = M[i + (1 << (j - 1))][j - 1];
}
Để tính ta dựa vào 2 đoạn con độ dài phủ hết , với :
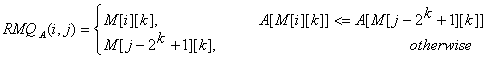
Độ phức tạp tổng quát của thuật toán này là
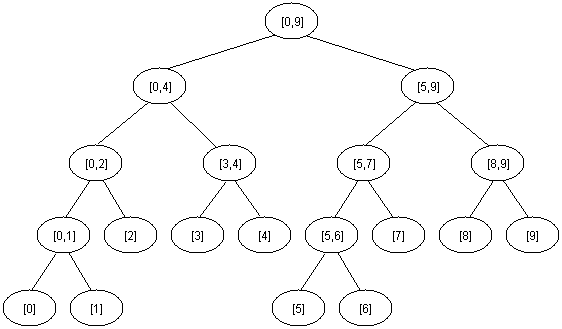
¶ Cây phân đoạn (segment tree, interval tree, range tree)
Ta biểu diễn cây bằng một mảng với là vị trí có giá trị nhỏ nhất trong đoạn mà nút quản lý.
Khởi tạo:
void initialize(intnode, int b, int e, int M[MAXIND], int A[MAXN], int N)
{
if (b == e)
M[node] = b;
else
{
// Khởi tạo nút con trái và nút con phải
initialize(2 * node, b, (b + e) / 2, M, A, N);
initialize(2 * node + 1, (b + e) / 2 + 1, e, M, A, N);
// Tính giá trị nhỏ nhất dựa trên 2 nút con
if (A[M[2 * node]] <= A[M[2 * node + 1]])
M[node] = M[2 * node];
else
M[node] = M[2 * node + 1];
}
}
Truy vấn:
int query(int node, int b, int e, int M[MAXIND], int A[MAXN], int i, int j)
{
int p1, p2;
// Đoạn cần tính không giao với đoạn của nút hiện tại
// --> return -1
if (i > e || j < b)
return -1;
// Đoạn cần tính nằm trong hoàn toàn trong đoạn của nút hiện tại
// --> return M[node]
if (b >= i && e <= j)
return M[node];
// Tìm giá trị nhỏ nhất trong 2 cây con trái và cây con phải
p1 = query(2 * node, b, (b + e) / 2, M, A, i, j);
p2 = query(2 * node + 1, (b + e) / 2 + 1, e, M, A, i, j);
// Tìm giá trị nhỏ nhất trong các cây con
if (p1 == -1)
return M[node] = p2;
if (p2 == -1)
return M[node] = p1;
if (A[p1] <= A[p2])
return M[node] = p1;
return M[node] = p2;
}
Mỗi truy vấn sẽ được thực hiện trong và thuật toán có độ phức tạp tổng quát là
¶ Bài toán LCA
¶ Thuật toán
Thuật toán đơn giản nhất như sau:
- Đặt là độ cao của đỉnh .
- Để trả lời truy vấn , . Không làm mất tính tổng quát, giả sử .
- Ta đi từ đến , với là tổ tiên của và .
- Ta đồng thời đi từ và lên cha của nó, đến khi 2 đỉnh này trùng nhau (lúc đó cả 2 đỉnh đều ở LCA).
![]()
Ví dụ:
- Ta cần tìm LCA của và . Ban đầu .
- Ta đi từ đến tổ tiên của mà có : Đi từ lên lên .
- Sau đó đồng thời đi từ và lên cha của nó đến khi 2 đỉnh bằng nhau:
function LCA(u, v):
if h(u) < h(v):
swap(u, v)
while h(u) > h(v):
u = parent(u)
while u != v:
u = parent(u)
v = parent(v)
return u
¶ Thuật toán
Ý tưởng chia input thành các phần bằng nhau như trong bài toán cũng có thể được sử dụng với . Chúng ta sẽ chia cây thành phần, với là chiều cao cây. Phần đầu bao gồm các tầng từ đến , phần 2 sẽ gồm các tầng từ đến ,...:
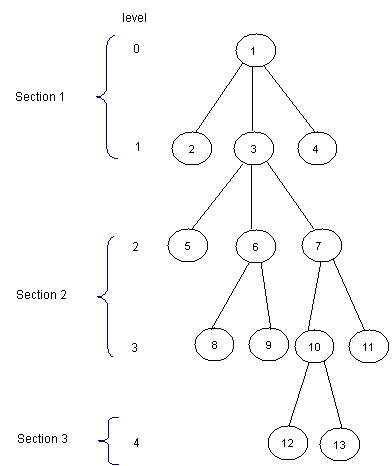
Giờ với mỗi nút chúng ta có thể biết được nút tổ tiên ở phần ngay trên nó. Ta sẽ tính giá trị này sử dụng mảng :

Ta có thể tính bằng DFS ( là cha của , và là tầng của nút )
void dfs(int node, int T[MAXN], int N, int P[MAXN], int L[MAXN], int nr) {
int k;
// Nếu nút ở phần đầu tiên, thì P[node] = 1
// Nếu nút ở đầu của 1 phần, thì P[node] = T[node]
// Trường hợp còn lại, P[node] = P[T[node]]
if (L[node] < nr)
P[node] = 1;
else
if(!(L[node] % nr))
P[node] = T[node];
else
P[node] = P[T[node]];
// DFS xuống các con
for each son k of node
dfs(k, T, N, P, L, nr);
}
Truy vấn:
int LCA(int T[MAXN], int P[MAXN], int L[MAXN], int x, int y)
{
// Nếu còn nút ở phần tiếp theo không phải là tổ tiên của cả x và y,
// ta nhảy lên phần tiếp theo. Đoạn này cũng tương tự như thuật toán
// <O(1), O(N)> nhưng thay vì nhảy từng nút, ta nhảy từng đoạn.
while (P[x] != P[y])
if (L[x] > L[y])
x = P[x];
else
y = P[y];
// Giờ x và y ở cùng phần. Ta tìm LCA giống như thuật <O(1), O(N)>
while (x != y)
if (L[x] > L[y])
x = T[x];
else
y = T[y];
return x;
}
Hàm này sử dụng tối đa phép toán. Với cách tiếp cận này chúng ta có thuật toán , trong trường hợp tệ nhất thì nên độ phức tạp tổng quát của thuật toán là .
¶ Thuật toán
Ứng dụng Sparse Table chúng ta có một thuật toán nhanh hơn. Đầu tiên chúng ta tính một bảng với là tổ tiên thứ của :
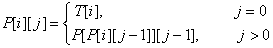
Code:
void process3(int N, int T[MAXN], int P[MAXN][LOGMAXN])
{
int i, j;
// Khởi tạo
for (i = 0; i < N; i++)
for (j = 0; 1 << j < N; j++)
P[i][j] = -1;
// Khởi tạo cha thứ 2^0 = 1 của mỗi nút
for (i = 0; i < N; i++)
P[i][0] = T[i];
// Quy hoạch động
for (j = 1; 1 << j < N; j++)
for (i = 0; i < N; i++)
if (P[i][j - 1] != -1)
P[i][j] = P[P[i][j - 1]][j - 1];
}
Bước khởi tạo này tốn bộ nhớ lẫn thời gian.
Cách tìm LCA giống hệt như thuật toán , nhưng để tăng tốc, thay vì nhảy lên cha ở mỗi bước, thì ta dùng mảng để nhảy, từ đó thu được độ phức tạp cho mỗi bước. Cụ thể:
- Gọi là độ cao của nút . Để tính , giả sử , đầu tiên ta tìm là tổ tiên của và có :
- Rõ ràng, ta cần nhảy từ lên cha thứ . Ta chuyển sang hệ 2. Duyệt từ xuống , nếu tổ tiên thứ của không cao hơn thì ta cho nhảy lên tổ tiên thứ của nó.
- Sau khi và đã ở cùng tầng, ta sẽ tính : cũng như trên, ta sẽ duyệt từ xuống , nếu tổ tiên thứ của và khác nhau thì chắc chắn sẽ ở cao hơn, khi đó ta sẽ cho cả và nhảy lên tổ tiên thứ của nó. Cuối cùng thì và sẽ có cùng cha, vậy nên khi đó .
Code:
function LCA(N, P[MAXN][MAXLOGN], T[MAXN], h[MAXN], u, v):
if h(u) < h(v):
// Đổi u và v
swap(u, v)
log = log2( h(u) )
// Tìm tổ tiên u' của u sao cho h(u') = h(v)
for i = log .. 0:
if h(u) - 2^i >= h(v):
u = P[u][i]
if u == v:
return u
// Tính LCA(u, v):
for i = log .. 0:
if P[u][i] != -1 and P[u][i] != P[v][i]:
u = P[u][i]
v = P[v][i]
return T[u];
Mỗi lần gọi hàm này chỉ tốn tối đa phép toán. Trong trường hợp tệ nhất thì nên độ phức tạp tổng quát của thuật toán này là .
Bài toán LCA còn có nhiều cách giải thú vị khác. Các bạn có thể tham khảo thêm trong bài viết này.
¶ Từ LCA đến RMQ
Ta có thể biến đổi bài toán LCA thành bài toán RMQ trong thời gian tuyến tính, do đó mà mọi thuật toán để giải bài toán RMQ đều có thể sử dụng để giải bài toán LCA. Hãy cùng xét ví dụ sau:
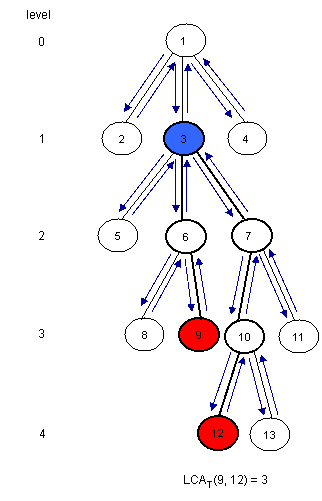

Để ý rằng là nút gần gốc nhất xuất hiện giữa lúc thăm và trong phép duyệt DFS. Vì thế ta có thể xét tất cả các phần tử giữa các cặp chỉ số bất kì của và trong dãy Euler Tour và tìm nút cao nhất. Ta xây dựng 3 mảng:
-
: dãy thứ tự thăm của các nút trên đường đi Euler, là nút được thăm thứ trên đường đi.
-
: tầng của các nút, là tầng của nút
-
: là vị trí xuất hiện đầu tiên của nút trên Euler Tour
Gỉa sử . Dễ thấy việc cần làm lúc này là tìm nút có nhỏ nhất trên . Do đó . Ví dụ:
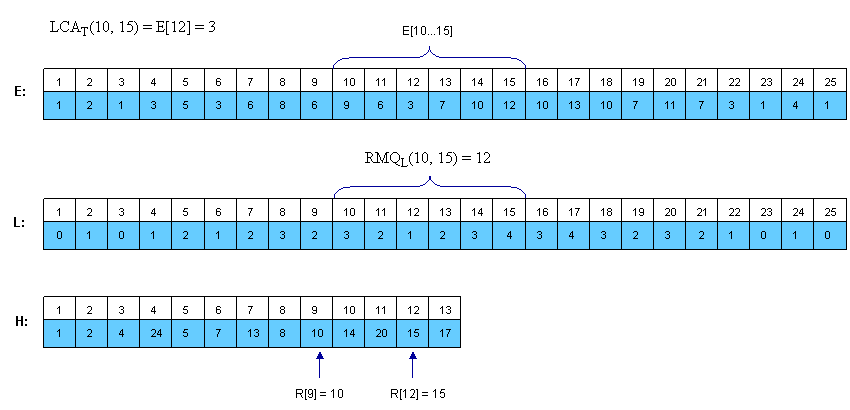
Cũng dễ thấy là mỗi 2 phần tử liên tiếp trong đều hơn kém nhau đúng 1 đơn vị.
¶ Từ RMQ đến LCA
Một cây Cartesian của một dãy là một cây nhị phân có gốc là phần tử nhỏ nhất trong và có vị trí . Cây con trái của là cây Cartesian của nếu , ngược lại thì không có. Cây con phải của là cây Cartesian của .
Dễ thấy rằng .
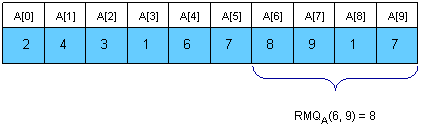
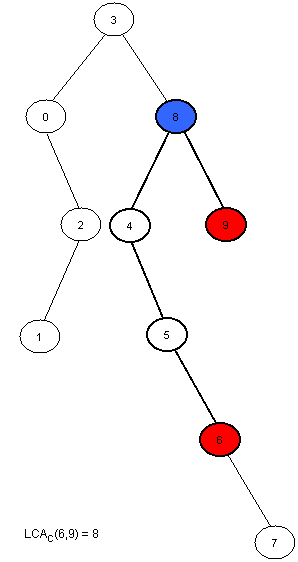
Bây giờ việc cần làm chỉ còn là tính trong thời gian tuyến tính. Chúng ta sẽ sử dụng một cái stack.
-
Ban đầu stack rỗng. Ta lần lượt đẩy các phần tử của vào stack.
-
Tại bước thứ , sẽ được đẩy vào ngay cạnh phần tử cuối cùng không lớn hơn trong stack, các phần tử lớn hơn bị loại khỏi stack. Phần tử trong stack ở vị trí của trước khi chèn vào sẽ là con trái của , còn sẽ là con phải của phần tử trước nó trong stack. Ở mỗi bước thì phần tử đầu tiên trong stack sẽ là gốc của cây Cartesian.
Ví dụ đối với cây ở trên:
| Bước | Stack | Sự hình thành cây |
|---|---|---|
| 0 | 0 | 0 là nút duy nhất trong cây |
| 1 | 0 1 | 1 được đẩy vào cuối stack. Giờ 1 là con phải của 0 |
| 2 | 0 2 | A[2] < A[1]. Lúc này 2 là con phải của 0 và con trái của 2 là 1 |
| 3 | 3 | A[3] hiện đang là phần tử nhỏ nhất cho nên mọi phần tử của stack bị lấy ra ra và 3 trở thành gốc cây. Con trái của 3 là 0 |
| 4 | 3 4 | 4 được thêm vào cạnh 3 và con phải của 3 là 4 |
| 5 | 3 4 5 | 5 được thêm vào cạnh 4, con phải của 4 là 5 |
| 6 | 3 4 5 6 | 6 được thêm vào cạnh 5, con phải của 5 là 6 |
| 7 | 3 4 5 6 7 | 7 được thêm vào cạnh 6, con phải của 6 là 7 |
| 8 | 3 8 | 8 được thêm vào cạnh 3, các phần tử lớn hơn bị loại bỏ. 8 giờ là con phải của 3 và con trái của 8 là 4 |
| 9 | 3 8 9 | 9 được thêm vào cạnh 8, con phải của 8 là 9 |
Vì mỗi phần tử của đều chỉ đẩy vào và lấy ra 1 lần nên độ phức tạp thuật toán là .
void computeTree(int A[MAXN], int N, int T[MAXN]) {
int st[MAXN], i, k, top = -1;
// Bắt đầu với stack rỗng
// Ở bước thứ i ta đẩy i và stack
for (i = 0; i < N; i++)
{
//Tìm vị trí của phần tử đầu tiên nhỏ hơn hoặc bằng A[i] trong stack
k = top;
while (k >= 0 && A[st[k]] > A[i])
k--;
// Chỉnh sửa cây theo mô tả ở trên
if (k != -1)
T[i] = st[k];
if (k < top)
T[st[k + 1]] = i;
// Đẩy i vào stack rồi xóa các phần tử lớn hơn A[i]
st[++k] = i;
top = k;
}
// Phần tử đầu tiên trong stack là gốc cây nên nó không có cha
T[st[0]] = -1;
}
¶ Thuật toán cho bài toán RMQ thu hẹp
Bài toán phát sinh khi giải bài toán LCA chỉ là trường hợp đặc biệt của bài toán RMQ tổng quát, do ta có điều kiện với mọi (lý do là 2 phần tử liên tiếp có quan hệ cha con với nhau). Ta gọi bài toán này là bài toán RMQ thu hẹp. Trong 1 số tài liệu còn được gọi là bài toán . Trong mục này, ta sẽ nghiên cứu một thuật toán có độ phức tạp tốt hơn cho bài toán RMQ thu hẹp.
Hãy biến đổi thành một dãy nhị phân có phần tử, với . Như vậy và chỉ nhận giá trị hoặc .
Chúng ta chia thành các block kích thước . Gọi là giá trị nhỏ nhất trong block thứ và là vị trí của giá trị nhỏ nhất này trong . Cả và đều có phần tử. Tính Sparse Table cho , tốn về bộ nhớ và thời gian.
Dùng sparse table cho mảng , ta tính được giá trị nhỏ nhất của 1 vài block trong . Nhưng ta vẫn cần tính giữa 2 vị trí bất kì trong cùng một block. Để làm được điều này, nhận thấy là một dãy nhị phân, mà mỗi block có phần tử. Vì số lượng dãy nhị phân độ dài là là một số khá nhỏ nên chúng ta có thể tính được mảng , với là giá trị nhỏ nhất trong các bit từ đến của dãy nhị phân . Dễ dàng khởi tạo bằng quy hoạch động trong cả thời gian và bộ nhớ . Chú ý rằng, ta cũng cần biết giá trị trong với mỗi block của mảng . Do đó, ta cần khởi tạo mảng với phần tử, mỗi phần tử cho biết giá trị của block tương ứng.
Kết hợp mảng , với Sparse table cho mảng , ta có thể trả lời truy vấn trong . Ta có 2 trường hợp:
- và thuộc cùng block.
- Ta dùng mảng để biết dãy nhị phân ở block chứa và .
- Tính và là vị trí của và trong block.
- Kết quả chính là .
- và thuộc 2 block khác nhau: kết quả sẽ là giá trị nhỏ nhất của 3 giá trị:
- Giá trị nhỏ nhất của các phần tử trong block chứa và nằm bên phải :
- Dùng mảng để biết được giá trị của dãy nhị phân của block chứa là .
- Tính chỉ số của trong block chứa là .
- Kết quả chính là .
- Giá trị nhỏ nhất của các phần tử trong block chứa và nằm bên trái : làm tương tự trường hợp trên
- Giá trị nhỏ nhất của các phần tử thuộc các block nằm giữa block chứa và block chứa . Dùng Sparse table cho , ta dễ dàng tính
được giá trị này trong .
¶ Một số bài để luyện tập
- CF #278 Div 1 - B
- Bayan 2015 Contest Warm Up - D
- Hello 2015 (Div.1) - A
- LCA
- QTREE2
- HBTLCA
- UPGRANET
- VOTREE
- SRM 310 - Floating Median
- Lorenzo Von Matterhorn
- http://acm.pku.edu.cn/JudgeOnline/problem?id=1986
- http://acm.pku.edu.cn/JudgeOnline/problem?id=2374
- http://acmicpc-live-archive.uva.es/nuevoportal/data/problem.php?p=2045
- http://acm.pku.edu.cn/JudgeOnline/problem?id=2763
- http://acm.uva.es/p/v109/10938.html
- http://acm.sgu.ru/problem.php?contest=0&problem=155